
Week 5
Online/in-Person Graduate course, University of California, Riverside, Department of Physics and Astronomy, 2019
The Foundation of Applied Machine Learning
Spring 2019
Instructor: Prof. Bahram Mobasher
Teaching Assistance: Abtin Shahidi email abtin.shahidi–at–email.ucr.edu
Course webpage: https://abtinshahidi.github.io/teaching/2019-spring-foundation-machine-learning
« Go to Week 4
Go to Week 6 »
Week 5
Machine Learning: Clustering and Classification
What is machine learning?
In traditional programming we mainly deal with an input and we need to explicitly write program for machine to produce a desired output but in the machine learning way of programming you will give the input and output (usually a smaller set of desired outputs) and the machine will find the right program to model output.
That is why what we did last week was a simple example of machine learning. Fitting a polynomial(general model) by linear regression which at the end produced the desired model which was our polynomial with the right coefficient to be able to predict future instances. Learning from much smaller subset of possible data to predict the future instances.
General idea:
- Take a set of examples. (training data)
- Inferring some properties from the underlying model. (Model)
- Use the model found to predict future (unknown) data. (test set, new examples, …)
Machine learning algorithm can be classified in two groups based on the available data:
- Supervised learning: In this set of algorithm we are dealing with a labeled dataset and we are trying to predict the label for future instances. Here we are trying to find the conditional probability for our variables given a set of known examples.
- Unsupervised learning: In these methods of learning we usually have a data set without any label and we are trying to find an underlying patterns. In the language of probability, we are trying to find the probability density of the inputs. We want to come up with a prior probability distribution.
We are going to see that the Supervised learning is basically an optimization problem.
Clustering:
import numpy as np
import random
import matplotlib.pyplot as plt
# use LaTeX fonts in the plot
plt.rc('text', usetex=True)
plt.rc('font', family='serif')
Clustering is an optimization problem. But first let’s define some useful concepts:
Variability of a cluster: $V(c)$
This shows how much difference exist between each element of the cluster and the mean of the cluster.
\[\begin{equation*} V(c) = \sum_{x \in c} d(mean(c), x) \end{equation*}\]In which $c$ is a cluster, and $d(x_0,x_1)$ is the distance between them. Euclidean or even Minkowski distance)
Dissimilirity of the set of clusters: $D(C)$
This is a measure for a aggregate variablility of a set of clusters. And it is defined as:
\[\begin{equation*} D(C) = \sum_{c \in C} V(c) \end{equation*}\]Quick note on $d(x_0,x_1)$:
Usually we define the distance between two points to be Euclidean.
If we take two vectors as $X, Y \in \mathbb{R}^M$, we define the Euclidean distance to be:
\[\begin{equation*} d(\vec{X}, \vec{Y}) = \sqrt{\sum_{i=1}^M (X_i-Y_i)^2} \end{equation*}\]This is a special case for a more general class of distance definitions which are called the Minkowski distance, which is defined as:
\[\begin{equation*} d(\vec{X}, \vec{Y}) = \sqrt[n]{\sum_{i=1}^M (X_i-Y_i)^n} \end{equation*}\]Mathematically speaking, this is a definition of $L^p$ spaces (Lebesgue spaces) which themselves are part of Banach spaces.
Another special cases from Minkowski are the Taxicab distance (also known as Manhatan distance):
\[\begin{equation*} d(\vec{X}, \vec{Y}) = \sum_{i=1}^M \|X_i-Y_i\| \end{equation*}\]And the Tchebychev distance:
\[\begin{equation*} d(\vec{X}, \vec{Y}) = \lim_{n \to \infty}{\sqrt[n]{\sum_{i=1}^M (X_i-Y_i)^n}} \end{equation*}\]As an exercise, find the equivalent representation of a circle in 2-d Euclidean geometry, for different cases of n.
Let’s write the code for Minkowski distance:
def Minkowski_d(x1, x2, p=2):
""" Function from L^p
This is a function for defining a general distance measure between any
given N-dimensional vectors: x1, x2
INPUT:
------
x1 (list or array of floats) : First vector
x2 (list or array of floats) : Second vector
p (float) : The power in our Minkowski definition
OUTPUT:
-------
(float) : The Minkowski distance of power p
between x1 and x2
"""
# Assuming we have a list or an array of numbers
# Creating a variable for summation
_sum_=0
# Now we go through every element on the arrays and
# will find the distance and add them
for x1_, x2_ in zip(x1, x2):
dummy = pow(abs(x1_-x2_), p)
_sum_+=dummy
distance = pow(_sum_, 1/p)
return distance
Minkowski_d(np.linspace(1,100,200), np.zeros(200), 10.4)
132.13424701384332
Continuing on Variability of a cluster:
Now if you look at the definition of Variability, you see that for the special case of Euclidean distance we are just missing a factor of $1/\sqrt{k}$ in which $k$ is the number of points in a given cluster, from the definition of variance.
What does it mean to not include the number of points in a cluster when calculating variability?
By doing that we are assigning higher variability to the larger cluster than the smaller cluster of the same variance.
You may have guessed by now, that we are trying to come up with an objective function for our optimization problem. So we can ask for a set of clusters that would minimize the dissimilarity of the clusters.
But if we put a cluster on each point, we are going to get zero dissimilarity which obviously is not a useful answer. For avoiding this we need to define a constraint; for example, we can constrain the total distance between clusters to be smaller than some value, or enforce a maximum number for clusters.
Hierarchical Clustering:
In this method of clustering we do the following:
Naive algorithm:
Assign a cluster to each point, so $N$ clusters for $N$ points.
Find the most similar clusters and merge them together. Now we have $N-1$ clusters.
We do the second part until we get to a cluster that contains all of the $N$ points.
This is the Agglomerative hierarchical clustering.
Now we need to quantify what we mean by similarity (linkage) of two clusters.
These are Linkage Metrics:
Single-linkage: It is the shortest distance between any member of one cluster and any memeber of another.
Complete Linkage: It is the greatest distance between any member of one cluster and any memeber of another.
Average Linkage: It is the average distance between any member of one cluster and any memeber of another.
Let’s look at the following example:
np.random.seed(500)
x1 = np.random.randint(0,10, 5)
x2 = np.random.randint(8,28, 6)
y1 = np.random.randint(0, 20, 5)
y2 = np.random.randint(15, 55, 6)
_x_, _y_ = list(x1), list(y1)
_x_.extend(list(x2))
_y_.extend(list(y2))
labels = np.arange(1, len(_x_)+1, 1)
plt.figure(figsize=(8,8))
plt.plot(x1, y1, "r." , markersize = 22)
plt.plot(x2, y2, "r.", markersize = 22)
for label, x, y in zip(labels, _x_, _y_):
plt.annotate(
label,
xy=(x, y), xytext=(-3, 3),
textcoords='offset points', ha='right', va='bottom', fontsize=16)
plt.show()
plt.show()
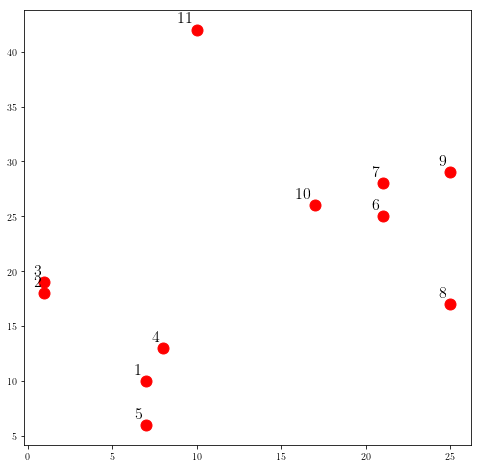
Now let’s use scipy for creating the dendogram for the hierarchical clustering:
import scipy.cluster.hierarchy
_data_ = np.c_[_x_,_y_]
links = scipy.cluster.hierarchy.linkage(_data_, method = "single", metric = "euclidean")
plt.figure(figsize=(10, 7))
scipy.cluster.hierarchy.dendrogram(
links,
orientation='top',
labels=labels,
distance_sort='descending',
show_leaf_counts=True,
)
plt.xlabel(r"Label of our data", fontsize = 19)
plt.ylabel(r"Number of steps toward smaller number of clusters", fontsize = 17)
plt.show()
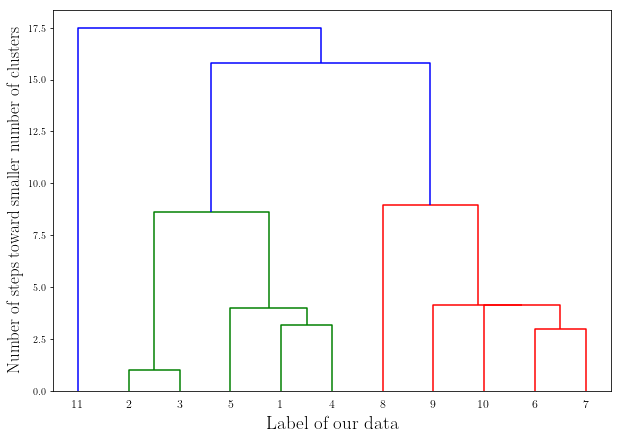
This is our resulting dendogram that contains all of the possible clustering following the algorithm mentioned above.
few notes:
This is completely deterministic for a given linkage metric.
The answer might not be optimal, since the hierarchical clustering is a greedy algorithm. In other words, your answer could be optimal but not globally optimal.
However, this can become very slow and the number of calculations grows with $O(N^3)$ which can become useless quickly.
However for some linkage metrics (i.e. single-linkage), there exist $O(N^2)$ algorithms but still not very fast.
k-means clustering:
If you know how many clusters you want then this is going to be a better choice since it is much faster. ($k$ is the number of clusters we want)
1. Start by randomly choosing k examples
as our initial centeroid.
2. create k clusters by assigning examples
to closest cendroid.
3. Assign a new values for the centeroid:
The average of previous cluster configuration.
4. Go to (2) while centroids are changing, else break.
We have our final configuration.
Important: Notice that the algorithm is not deterministic and the result can change by choosing another initial configuration.
How much time it takes to run the algorithm once before getting to the 4th line?
For $N$ and $k$ clusters we need to find $kN$ distances. Which is much smaller than $O(N^2)$. Also, we will see that we do not need to go through many iteration to converge. (Relative to $N$)
plt.figure(figsize=(8,8))
plt.plot(_x_, _y_, ".", markersize = 14)
plt.show()
These are some 2-d data points and you want to find a clustering for them.
Let’s define some classes!
First class is Point which contains information about a given data point:
class Point:
def __init__(self, features, label = None, \
name = "Unassigned"):
self.name = name
self.features = features
self.label = label
# get the dimensionality of the features
def get_dimension(self):
return len(self.features)
def get_features(self):
return self.features
def get_label(self):
return self.label
def get_name(self):
return self.name
def distance_Minkowski(self, other, p = 2):
return Minkowski_d(self.features, other.get_features(), p)
distance_Minkowski.__doc__ = Minkowski_d.__doc__
def get_norm(self, p = 2):
_zero_=[0 for _ in range(self.get_dimension())]
return Minkowski_d(self.features, _zero_, p)
def __str__(self):
return self.name +" : "+ str(self.features) + ' : '\
+ str(self.label)
Our second class is the class of Cluster, which contains several data points. (Point objects)
class Cluster:
def __init__(self, points):
self.points = points
self.centroid = self.find_centroid()
def find_centroid(self):
_sum_ = np.zeros(self.points[0].get_dimension())
for point in self.points:
_sum_+=np.array(point.get_features())
Centroid_vec = _sum_/len(self.points)
centroid = Point(Centroid_vec, name = "Centroid")
return centroid
def update(self, points):
# Keep the old centroid
previous_centroid = self.centroid
# Update the Cluster attribiutes
self.points = points
self.centroid = self.find_centroid()
return self.centroid.distance_Minkowski(previous_centroid)
def variability(self, p = 2):
_sum_distances_=0
for point in self.points:
_sum_distances_ += point.distance_Minkowski(self.centroid, p)
return _sum_distances_
def Elements(self):
for point in self.points:
yield point
def __str__(self):
names = []
for point in self.points:
names.append(point.get_name())
names.sort()
info = "Cluster Centroid: " \
+ str(self.centroid.features) + "contains:" + "\n"
for name in names:
info = info + name + ", "
return info[:-2] #remove trailing comma and space
def Dissimilarity(_clusters_, p = 2):
_tot_vari = 0
for _cluster_ in _clusters_:
_tot_vari += _cluster_.variability(p)
return _tot_vari
Driver’s dataset:
Let’s download a delivery fleet data set: data set
data = {}
with open("data_drivers.data", 'r') as f:
lines = f.readlines()
header = lines[0].split()
for i, col in enumerate(header):
x = []
for line in lines[1:]:
x.append(float(line.split()[i]))
data[col] = x
data.keys()
dict_keys(['Driver_ID', 'Distance_Feature', 'Speeding_Feature'])
plt.figure(figsize=(10,7))
plt.scatter(data["Distance_Feature"], data["Speeding_Feature"])
plt.xlabel(r"Distance Feature", fontsize = 18)
plt.ylabel(r"Speeding Feature", fontsize = 18)
plt.show()
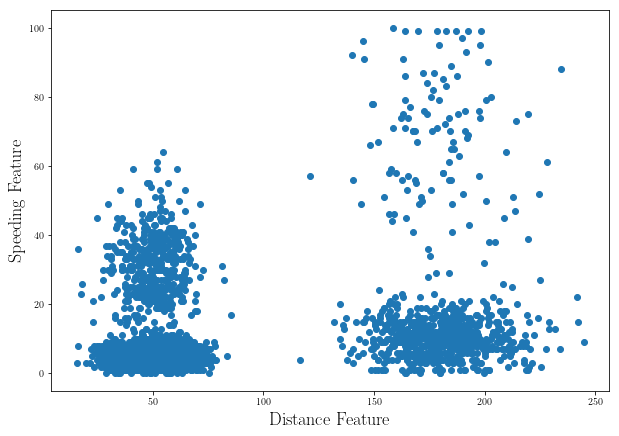
_points_ = []
for i in range(len(data["Driver_ID"])):
features = [data["Distance_Feature"][i], data["Speeding_Feature"][i]]
P = Point(features, name = data["Driver_ID"][i])
_points_.append(P)
def K_Means_Clustering(points, k, verbose = False):
# Get k random initial centroids, create cluster for each
initial_centroids = random.sample(points, k)
clusters = []
for centroid in initial_centroids:
clusters.append(Cluster([centroid]))
#Iterate until centroids don't move
converged = False
number_iterations = 0
while not converged:
number_iterations += 1
#Create a list containing k distinct empty lists
new_clusters = []
for i in range(k):
new_clusters.append([])
# Associate each example with closest centroid
for p in points:
# Find the closest centroid
smallest_distance = p.distance_Minkowski(clusters[0].find_centroid())
idi = 0
for i in range(1, k):
distance = p.distance_Minkowski(clusters[i].find_centroid())
if distance < smallest_distance:
smallest_distance = distance
idi = i
#Add p to the list of examples for appropriate cluster
new_clusters[idi].append(p)
for c in new_clusters: # Avoid having empty clusters
if len(c) == 0:
raise ValueError('Empty Cluster')
# Update each cluster; check if a centroid has changed
converged = True
for i in range(k):
if clusters[i].update(new_clusters[i]) > 0.0:
converged = False
if verbose:
print('Iteration #' + str(number_iterations))
for c in clusters:
print(c)
print('') #add blank line
return clusters
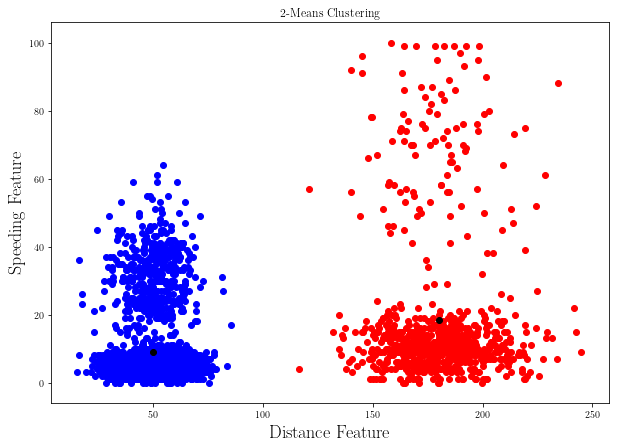
clusters = K_Means_Clustering(_points_, 2)
color = "b"
plt.figure(figsize=(10,7))
for cluster in clusters:
for p in list(cluster.points):
plt.scatter(p.get_features()[0], p.get_features()[1], color = color)
color = "r"
plt.scatter(cluster.find_centroid().get_features()[0], cluster.find_centroid().get_features()[1], color = "k")
plt.title(r"2-Means Clustering")
plt.xlabel(r"Distance Feature", fontsize = 18)
plt.ylabel(r"Speeding Feature", fontsize = 18)
plt.show()
Can take a long time to execute next cell!
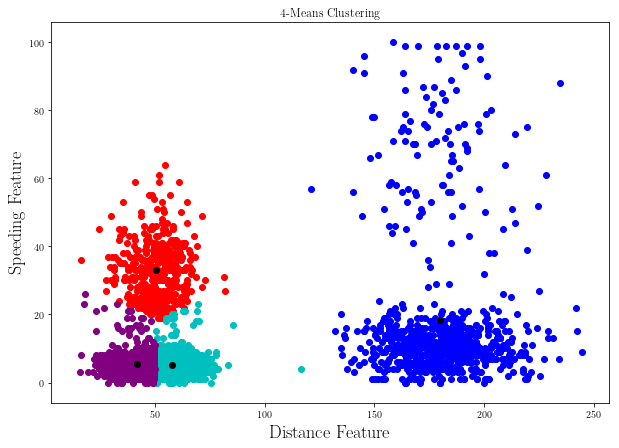
clusters = K_Means_Clustering(_points_, 4)
plt.figure(figsize=(10,7))
colors = ["b", "r", "c", "purple"]
for i, cluster in enumerate(clusters):
for p in list(cluster.points):
plt.scatter(p.get_features()[0], p.get_features()[1], color = colors[i])
plt.scatter(cluster.find_centroid().get_features()[0], cluster.find_centroid().get_features()[1], color = "k")
plt.title(r"4-Means Clustering", fontsize = 20)
plt.xlabel(r"Distance Feature", fontsize = 18)
plt.ylabel(r"Speeding Feature", fontsize = 18)
plt.show()
Feature scaling:
One of the most important thing to remember is that our definition of the distance give the same weight to different dimension, so we need to be careful that our data is not skewed toward a dimension. For reaching this goal we can use feature scaling methods.
One way to do this:
# This is called Z-scaling
def scale_feature(_feature_):
_f_ = np.array(_feature_)
zero_f_ = _f_ - np.average(_f_)
std = np.std(_f_)
return zero_f_/std
_points_ = []
for i in range(len(data["Driver_ID"])):
features = [scale_feature(data["Distance_Feature"])[i],
scale_feature(data["Speeding_Feature"])[i]]
P = Point(features, name = data["Driver_ID"][i])
_points_.append(P)
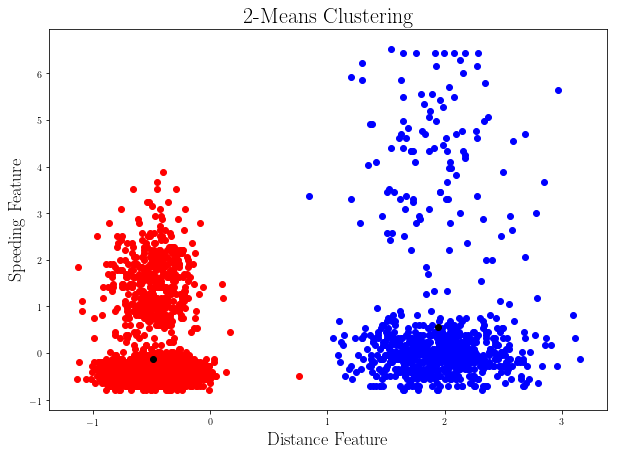
clusters = K_Means_Clustering(_points_, 2)
color = "b"
plt.figure(figsize=(10,7))
for cluster in clusters:
for p in list(cluster.points):
plt.scatter(p.get_features()[0], p.get_features()[1], color = color)
color = "r"
plt.scatter(cluster.find_centroid().get_features()[0], cluster.find_centroid().get_features()[1], color = "k")
plt.title(r"2-Means Clustering", fontsize = 22)
plt.xlabel(r"Distance Feature", fontsize = 18)
plt.ylabel(r"Speeding Feature", fontsize = 18)
plt.show()
Can take a long time to execute next cell!
clusters = K_Means_Clustering(_points_, 4)
plt.figure(figsize=(10,7))
colors = ["b", "r", "c", "purple"]
for i, cluster in enumerate(clusters):
for p in list(cluster.points):
plt.scatter(p.get_features()[0], p.get_features()[1], color = colors[i])
plt.scatter(cluster.find_centroid().get_features()[0], cluster.find_centroid().get_features()[1], color = "k")
plt.title(r"4-Means Clustering", fontsize = 22)
plt.xlabel(r"Distance Feature", fontsize = 18)
plt.ylabel(r"Speeding Feature", fontsize = 18)
plt.show()
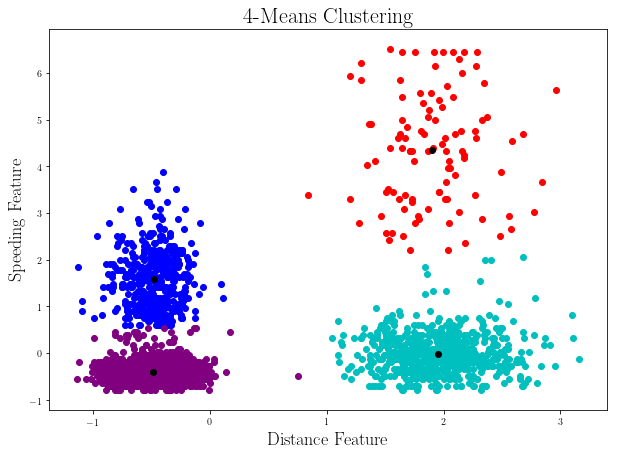
This seems more natural with respect to the 4-Means we did for the raw data in which the 4 clusters were different from what we see here.
This shows how important feature scaling can be!
How can we determine the number of clusters ($k$)?
- Usually we use our prior knowledge about the data.
- There are six type of plants. $k=6$
- There are five personality types. $k=5$
- There are two kinds of galaxy mergers. $k=2$
- Searching for $k$
- We can search through different values of $k$ and find the optimal.
- Using hierarchial clustering on subset of data
How can we make sure that we are not using a bad initial centroid?
Choose multiple sets of initial centroid at random
Run the k-means algorithm on above initial centroids
and find the solutions. Select the set of clusters for
which Dissimilarity (D(C)) would be minimized, at least
for our set of solutions.
Classification:
In the last part on clustering we were able to develop our first unsupervised learning algorithm. Here we are going to see how a supervised algorithm works. But first let’s talk about supervised learning.
Supervised learning:
- Regression:
- Fitting curve to data
- Finding a Real valued measure for data vector. (features)
- Classification:
- Associate each data vector to a label. (N-dimensional vector of features to a discrete value which are the labels.)
Nearest Neighbor:
One of the most commonly used algorithm for classification is nearest neighbor. In which you just remember the data you trained on and you will not perform any fancy manipulation on the data.
Basic algorithm is as follows:
* Find the nearest example from the training data to the new data.
* Assign the known label of that example to your new data.
Let’s imagine the following labeled points in your data set:
fig_cl_1 = plt.figure(figsize=(8,8))
group_1, group_2 = [], []
random.seed(50)
for i in range(50):
_p_ = Point([random.randint(0, 50), random.randint(20, 60)], label="red")
group_1.append(_p_)
plt.scatter(_p_.get_features()[0], _p_.get_features()[1], color = "r")
_p_ = Point([random.randint(20, 60), random.randint(40, 80)], label="blue")
group_2.append(_p_)
plt.scatter(_p_.get_features()[0], _p_.get_features()[1], color = "b")
plt.xlabel(r"Feature 1", fontsize = 19)
plt.ylabel(r"Feature 2", fontsize = 19)
plt.show()
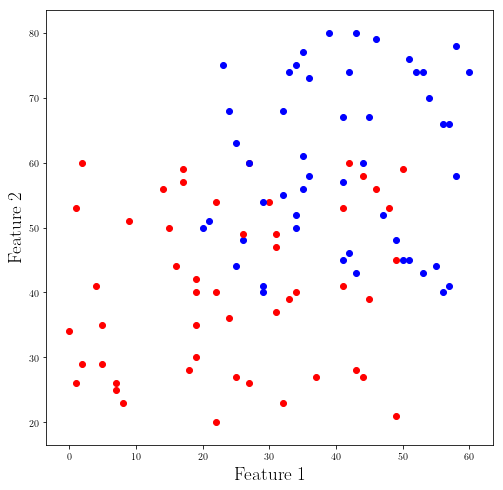
Now let’s say we have a new data point which we are trying to assign the labels “red” and “blue” to it based on the training data. (data we already have)
The easiest way to deal with that is to consider the label from the nearest neighbor in terms of our distant measure.
new_data = [36, 49]
New_data = Point(new_data, label="None")
groups = group_1
groups.extend(group_2)
minimum_distance = New_data.distance_Minkowski(group_1[0])
for point in groups:
_distance_ = New_data.distance_Minkowski(point)
if _distance_<= minimum_distance:
minimum_distance = _distance_
New_data.label = point.get_label()
print(minimum_distance, New_data.label)
13.0 red
9.219544457292887 red
5.385164807134504 red
5.0 red
3.605551275463989 blue
2.23606797749979 blue
fig_cl_1 = plt.figure(figsize=(8,8))
for point in groups:
plt.plot(point.get_features()[0], point.get_features()[1], ".",
color = point.get_label(), markersize = 12)
plt.plot(New_data.get_features()[0], New_data.get_features()[1], "*",
color = New_data.get_label(), markersize = 15)
plt.xlabel(r"Feature 1", fontsize = 19)
plt.ylabel(r"Feature 2", fontsize = 19)
plt.show()
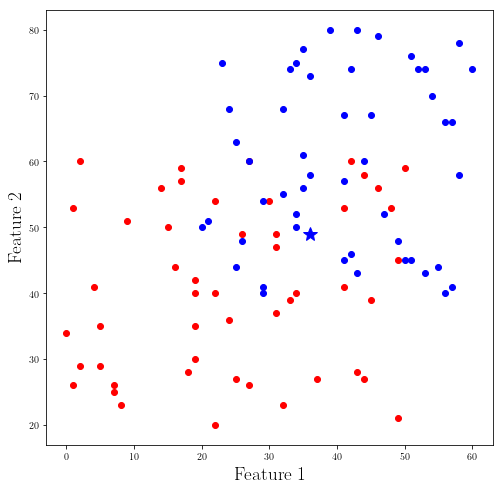
And you can see with our code we found the nearest element in the data set to our new data (star) and we assigned the closest existing label.
This approach has a problem since we only look at the nearest neighbor in which we can mislead us quite easily particularly if we have a noisy data set. For avoiding this issue we will introduce another method:
K-Nearest Neighbors: (KNN)
This is very similar to nearest neighbor algorithm but this time we are looking for K nearest neighbors and to take the most occurred label of those K neighbors as your prediction for new data.
All that said, you should remember that by increasing K you are making the size of your “true” lables more relevant. Which will increase your error in predicting labels for new data.
Let’s look at another famous dataset called iris plants dataset.
First, let’s read the information file called iris.names:
with open("iris.names", "r") as info_file:
lines = info_file.readlines()
info_file.close()
lines[:8]
['1. Title: Iris Plants Database\n',
'\tUpdated Sept 21 by C.Blake - Added discrepency information\n',
'\n',
'2. Sources:\n',
' (a) Creator: R.A. Fisher\n',
' (b) Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)\n',
' (c) Date: July, 1988\n',
'\n']
lines[-20:]
['7. Attribute Information:\n',
' 1. sepal length in cm\n',
' 2. sepal width in cm\n',
' 3. petal length in cm\n',
' 4. petal width in cm\n',
' 5. class: \n',
' -- Iris Setosa\n',
' -- Iris Versicolour\n',
' -- Iris Virginica\n',
'\n',
'8. Missing Attribute Values: None\n',
'\n',
'Summary Statistics:\n',
'\t Min Max Mean SD Class Correlation\n',
' sepal length: 4.3 7.9 5.84 0.83 0.7826 \n',
' sepal width: 2.0 4.4 3.05 0.43 -0.4194\n',
' petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)\n',
' petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)\n',
'\n',
'9. Class Distribution: 33.3% for each of 3 classes.\n']
features_by_index = {
0 : "sepal lenght",
1 : "sepal width",
2 : "petal lenght",
3 : "petal width",
4 : "class",
}
Now let’s look at the data itself from the file iris.data:
with open("iris.data", "r") as data_file:
data_lines = data_file.readlines()
data_file.close()
data_lines[:5]
['5.1,3.5,1.4,0.2,Iris-setosa\n',
'4.9,3.0,1.4,0.2,Iris-setosa\n',
'4.7,3.2,1.3,0.2,Iris-setosa\n',
'4.6,3.1,1.5,0.2,Iris-setosa\n',
'5.0,3.6,1.4,0.2,Iris-setosa\n']
_data_ = []
for d_line in data_lines:
# separating the words (strings) by comma ","
_line_ = d_line.split(",")
# reading the data and turning them into their correct types
_line_f = [float(e) for e in _line_[:-1]]
_line_f.append(_line_[-1][:-1])
# putting the data together
_data_.append(_line_f)
_data_[:4]
[[5.1, 3.5, 1.4, 0.2, 'Iris-setosa'],
[4.9, 3.0, 1.4, 0.2, 'Iris-setosa'],
[4.7, 3.2, 1.3, 0.2, 'Iris-setosa'],
[4.6, 3.1, 1.5, 0.2, 'Iris-setosa']]
_data_[-4:]
[[6.5, 3.0, 5.2, 2.0, 'Iris-virginica'],
[6.2, 3.4, 5.4, 2.3, 'Iris-virginica'],
[5.9, 3.0, 5.1, 1.8, 'Iris-virginica'],
['']]
_data_copy = _data_[:-1]
original_data_points = []
for i, _d_ in enumerate(_data_[:-1]):
_p_ = Point(_d_[:-1], label = _d_[-1], name=str(i+1))
original_data_points.append(_p_)
Now we have our data in form of a list of Point objects. But before looking at the data set let’s divide the dataset into training and test set. We should do this to avoid over-fitting or creating bias toward a particular model without having evidence.
def divide_dataset(_data_, training_fraction = 0.8, seed = random.randint(1,100000)):
"""
This is a general function to divide a given dataset into
training set and test set.
INPUT:
------
_data_ (list or an array) : contains data
training_fraction (float) : what fraction of data goes
to training set.
OUTPUT:
------
training_dataset (list) : contains the training data
test_dataset (list) : contains the test data
"""
_len_ = len(_data_)+1
_number_of_data_in_training_ = int(round(training_fraction*_len_))
random.seed(seed)
sample_indices = random.sample(range(len(_data_)), _number_of_data_in_training_)
test_dataset = []
training_dataset = []
for i, point in enumerate(_data_):
if i in sample_indices:
training_dataset.append(point)
else:
test_dataset.append(point)
return training_dataset, test_dataset
data_points, test_dataset = divide_dataset(original_data_points, training_fraction=0.8, seed = 1000)
x, y = [], []
for _p_ in data_points:
_x_ = _p_.get_features()[0]
_y_ = _p_.get_features()[1]
_colors_ = []
_labels_ = []
for point in data_points:
_label_ = point.get_label()
_labels_.append(_label_)
_label_copy = _labels_
# Getting unique labels with a simple trick of using "set" function ----> read the "set" doc by set.__doc__
unique_labels = list(set(_labels_))
print(unique_labels)
for _label_ in _labels_:
if _label_ == unique_labels[0]:
_colors_.append("r")
if _label_ == unique_labels[1]:
_colors_.append("g")
if _label_ == unique_labels[2]:
_colors_.append("b")
['Iris-versicolor', 'Iris-setosa', 'Iris-virginica']
iris_plot = plt.figure(figsize=(8,8))
x, y = [], []
for point in data_points:
x.append(point.get_features()[0]),
y.append(point.get_features()[1]),
_x_, _y_ = [[], [], []], [[], [], []]
x = np.array(x)
y = np.array(y)
_labels_=np.array(_labels_)
for i, _label_ in enumerate(unique_labels):
_x_[i] = x[_labels_==_label_]
_y_[i] = y[_labels_==_label_]
plt.plot(_x_[0], _y_[0], ".", markersize=14, label=unique_labels[0])
plt.plot(_x_[1], _y_[1], ".", markersize=14, label=unique_labels[1])
plt.plot(_x_[2], _y_[2], ".", markersize=14, label=unique_labels[2])
plt.xlabel(features_by_index[0], fontsize = 22)
plt.ylabel(features_by_index[1], fontsize = 22)
plt.legend(fontsize=15)
plt.show()
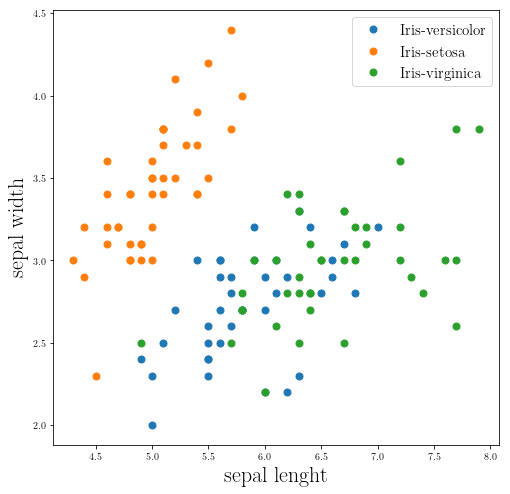
From the above plot you can see the sepal weight and lenght do not separate these groups. So let’s look at the rest of the data:
iris_plot_2 = plt.figure(figsize=(8,8))
x, y = [], []
for point in data_points:
x.append(point.get_features()[2]),
y.append(point.get_features()[3]),
_x_, _y_ = [[], [], []], [[], [], []]
x = np.array(x)
y = np.array(y)
_labels_=np.array(_labels_)
for i, _label_ in enumerate(unique_labels):
_x_[i] = x[_labels_==_label_]
_y_[i] = y[_labels_==_label_]
plt.plot(_x_[0], _y_[0], ".", markersize=14, label=unique_labels[0])
plt.plot(_x_[1], _y_[1], ".", markersize=14, label=unique_labels[1])
plt.plot(_x_[2], _y_[2], ".", markersize=14, label=unique_labels[2])
plt.xlabel(features_by_index[2], fontsize = 22)
plt.ylabel(features_by_index[3], fontsize = 22)
plt.legend(fontsize=15)
plt.show()
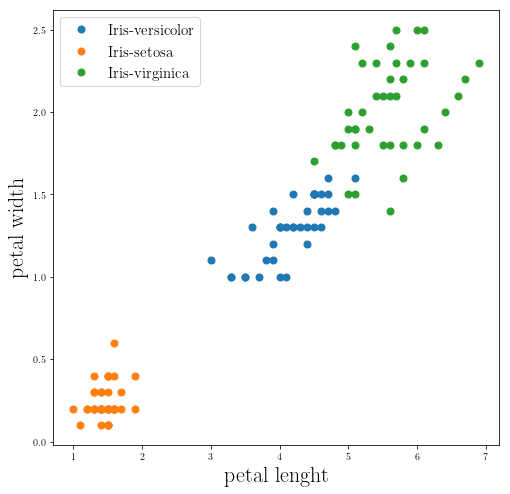
This is much better! we can see how petal can separate them into different groups.
iris_plot_2 = plt.figure(figsize=(8,8))
x, y = [], []
for point in data_points:
x.append(point.get_features()[0]),
y.append(point.get_features()[2]),
_x_, _y_ = [[], [], []], [[], [], []]
x = np.array(x)
y = np.array(y)
_labels_=np.array(_labels_)
for i, _label_ in enumerate(unique_labels):
_x_[i] = x[_labels_==_label_]
_y_[i] = y[_labels_==_label_]
plt.plot(_x_[0], _y_[0], ".", markersize=14, label=unique_labels[0])
plt.plot(_x_[1], _y_[1], ".", markersize=14, label=unique_labels[1])
plt.plot(_x_[2], _y_[2], ".", markersize=14, label=unique_labels[2])
plt.xlabel(features_by_index[0], fontsize = 22)
plt.ylabel(features_by_index[2], fontsize = 22)
plt.legend(fontsize=15)
plt.show()
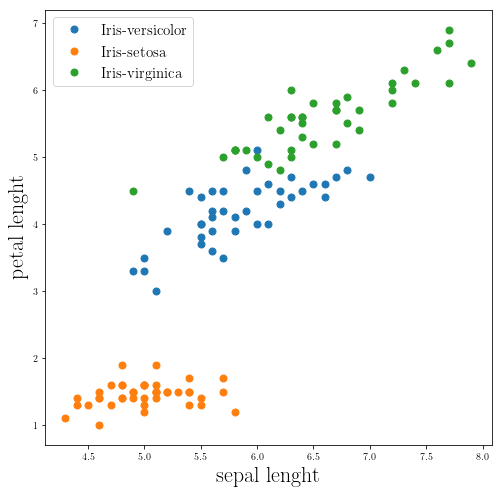
iris_plot_3 = plt.figure(figsize=(8,8))
x, y = [], []
for point in data_points:
x.append(point.get_features()[1]),
y.append(point.get_features()[3]),
_x_, _y_ = [[], [], []], [[], [], []]
x = np.array(x)
y = np.array(y)
_labels_=np.array(_labels_)
for i, _label_ in enumerate(unique_labels):
_x_[i] = x[_labels_==_label_]
_y_[i] = y[_labels_==_label_]
plt.plot(_x_[0], _y_[0], ".", markersize=14, label=unique_labels[0])
plt.plot(_x_[1], _y_[1], ".", markersize=14, label=unique_labels[1])
plt.plot(_x_[2], _y_[2], ".", markersize=14, label=unique_labels[2])
plt.xlabel(features_by_index[1], fontsize = 22)
plt.ylabel(features_by_index[3], fontsize = 22)
plt.legend(fontsize=15)
plt.show()
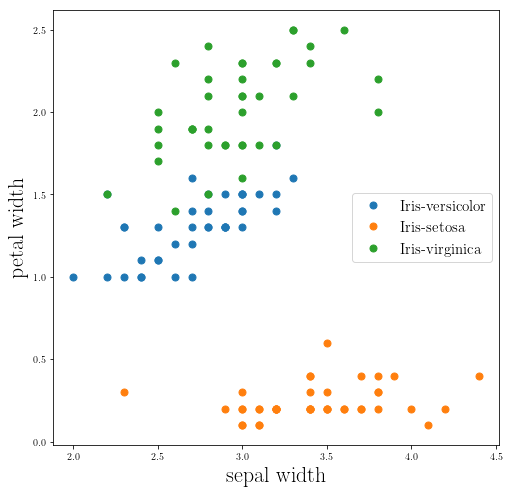
Now let’s implement the K-Nearest Neighbours algorithm:
def K_Nearest_Neighbours(new_point, points, k, verbose = False):
distances = []
for point in points:
distances.append((point.distance_Minkowski(new_point), point))
sorted_by_distance = sorted(distances, key= lambda x : x[0])
k_neighbours = [sorted_by_distance[i][1] for i in range(k)]
if verbose:
print([sorted_by_distance[i][0] for i in range(k)])
k_neighbours_labels = [k_neighbours[i].get_label() for i in range(k)]
most_frequent_label = max(set(k_neighbours_labels), key=k_neighbours_labels.count)
new_point_copy = Point(new_point.get_features(), label = most_frequent_label)
if verbose:
print(k_neighbours_labels)
return most_frequent_label, new_point_copy
new_point = Point([6, 3, 4.4, 2.5])
Remember that we are looking through all of the features:
_label_, _updated_point_ = K_Nearest_Neighbours(new_point, data_points, 7, True)
[0.7615773105863903, 0.8366600265340752, 0.8544003745317529, 0.8660254037844386, 0.9746794344808961, 0.989949493661166, 0.989949493661166]
['Iris-virginica', 'Iris-versicolor', 'Iris-virginica', 'Iris-virginica', 'Iris-virginica', 'Iris-virginica', 'Iris-virginica']
iris_plot_2 = plt.figure(figsize=(8,8))
x, y = [], []
for point in data_points:
x.append(point.get_features()[2]),
y.append(point.get_features()[3]),
_x_, _y_ = [[], [], []], [[], [], []]
x = np.array(x)
y = np.array(y)
_labels_=np.array(_labels_)
for i, _label_ in enumerate(unique_labels):
_x_[i] = x[_labels_==_label_]
_y_[i] = y[_labels_==_label_]
plt.plot(_x_[0], _y_[0], ".", markersize=14, label=unique_labels[0])
plt.plot(_x_[1], _y_[1], ".", markersize=14, label=unique_labels[1])
plt.plot(_x_[2], _y_[2], ".", markersize=14, label=unique_labels[2])
plt.plot(new_point.get_features()[2], new_point.get_features()[3], '*', markersize = 18, label=_label_)
plt.xlabel(features_by_index[2], fontsize = 22)
plt.ylabel(features_by_index[3], fontsize = 22)
plt.legend(fontsize=15)
plt.show()
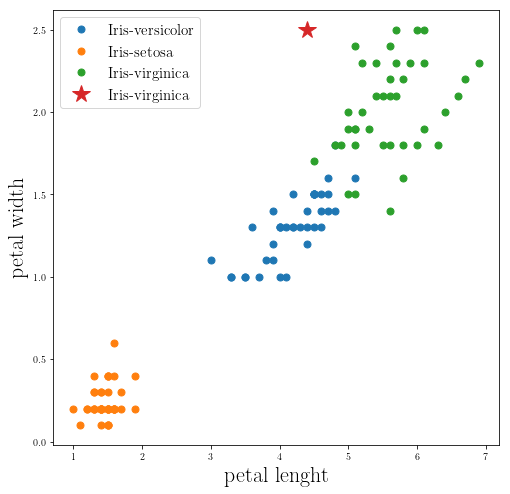
It seems that our code is working fine!
Let’s run the code on the test data set dataset:
def run_test(test_data, training_data, k):
updated_test_data = []
truely_assigned = 0
for point in test_data:
_label_, new = K_Nearest_Neighbours(point, training_data, k)
updated_test_data.append(new)
if new.get_label() == point.get_label():
truely_assigned+=1
return updated_test_data, truely_assigned/len(test_data)
Now that we have a function for let’s look at the number of times we are correctly categorizing plants:
In this part we are going to see whether if our score (sensitivity) increases with the fraction of data in the training set:
_t_span_ = np.linspace(0.05, 0.9, 30)
K = 5
accuracy =np.zeros(len(_t_span_))
for i, _t_ in enumerate(_t_span_):
training, test = devide_dataset(original_data_points, training_fraction=_t_)
assigned_test_data, accuracy[i] = run_test(test, training, K)
fig_training_frac_accuracy = plt.figure(figsize=(8, 8))
plt.plot(_t_span_, accuracy)
plt.xlabel(r"Fraction of dataset in our training set", fontsize = 18)
plt.ylabel(r"Accuracy of our prediction", fontsize = 18)
plt.show()
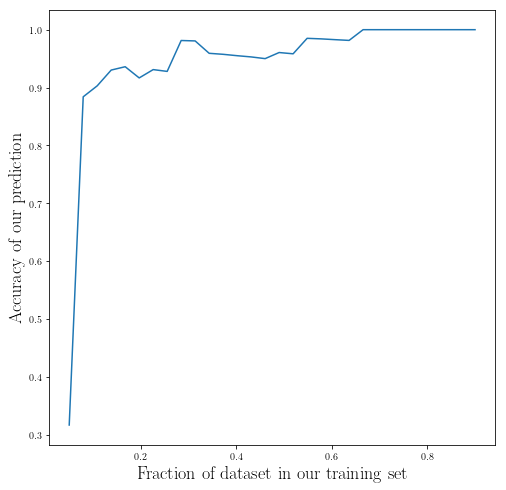
_t_1, _acc_1 = _t_span_, accuracy
You can see the performance of our model is not increase with adding more data after about 0.2 fraction.
Now let’s look at the performance of our model with increasing number of neighbours:
frac = 0.7
training, test = devide_dataset(original_data_points, training_fraction=frac)
_k_span_ = np.arange(1, len(training), 1)
accuracy=np.zeros(len(_k_span_))
for i, _k_ in enumerate(_k_span_):
assigned_test_data, accuracy[i] = run_test(test, training, _k_)
fig_training_frac_accuracy = plt.figure(figsize=(8, 8))
plt.plot(_k_span_, accuracy)
plt.xlabel(r"Number of neighbours $(k)$", fontsize = 18)
plt.ylabel(r"Accuracy of our prediction", fontsize = 18)
plt.show()
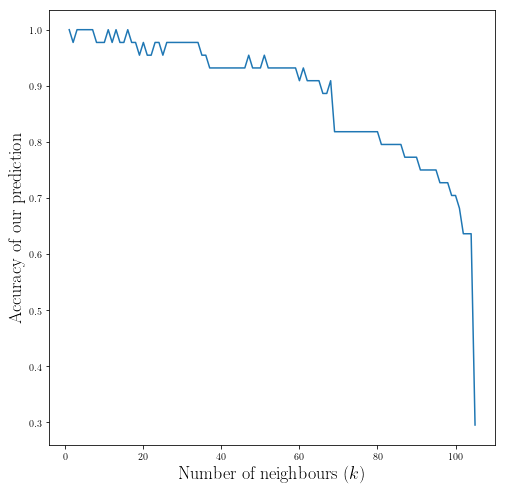
As you can see increasing the number of neighbours does not increase our performance after $(k>10)$ and our performance actually goes down!
k_2, _acc_2 = _k_span_, accuracy
Conclusion:
- Increasing the fraction of the training set does not always increase our performance.
- Increasing the number of neighbours to consider, does not increase our performance and it actually can makes our prediction to be worse!
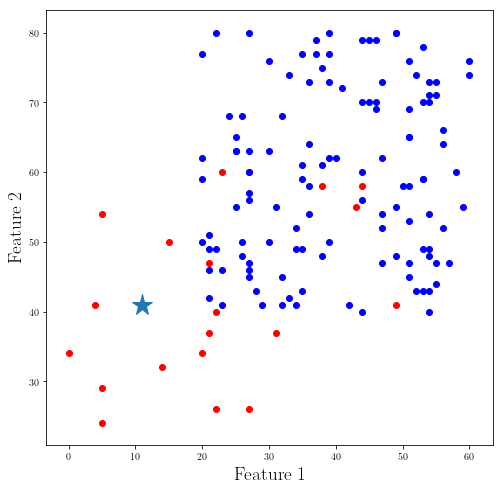
In all of our examples we considered, the number of points in each class were the same. Now let’s take a look at a case in which one class is dominating:
_fig_cl_1 = plt.figure(figsize=(8,8))
group_1, group_2 = [], []
group = []
random.seed(50)
new_point = Point([11, 41])
for i in range(20):
_p_ = Point([random.randint(0, 50), random.randint(20, 60)], label="red")
group_1.append(_p_)
plt.scatter(_p_.get_features()[0], _p_.get_features()[1], color = "r")
for i in range(120):
_p_ = Point([random.randint(20, 60), random.randint(40, 80)], label="blue")
group_2.append(_p_)
plt.scatter(_p_.get_features()[0], _p_.get_features()[1], color = "b")
group = group_1
group.extend(group_2)
plt.plot(new_point.get_features()[0], new_point.get_features()[1], "*", markersize = 22)
plt.xlabel(r"Feature 1", fontsize = 19)
plt.ylabel(r"Feature 2", fontsize = 19)
plt.show()
k_span = np.arange(1, 40)
labels = []
labels_numeric = []
for k in k_span:
label, _ = K_Nearest_Neighbours(new_point, group, k)
labels.append(label)
if label=="red":
labels_numeric.append(1)
else:
labels_numeric.append(-1)
plt.figure(figsize=(8,8))
plt.plot(k_span, labels_numeric)
plt.xlabel(r"Number of Neighbours", fontsize = 19)
plt.ylabel(r"Associated label (Red: 1, Blue: -1)", fontsize = 19)
plt.show()
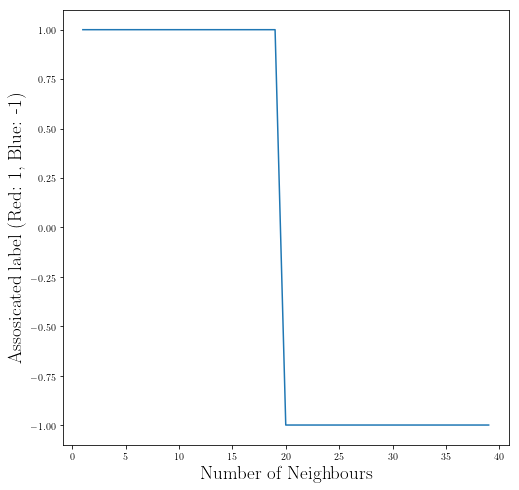
You can see when the number of instances in a class dominate another class/classes we need to be extra careful since we can visually see that our new data point is closer to being red but after about ~20 neighbours we are going to make many of our neighbours to be in the dominated class which make our prediction wrong!
Therefore, you should always consider the size of the classes and dataset before finding the right k. And we should always check our performance as well.
Let’s use scikit-learn for performing the same KNN algorithm:
from sklearn.preprocessing import LabelEncoder
Here we using LabelEncoder to change the labels into numbers:
_label_copy = [_data_copy[i][-1] for i in range(len(_data_copy))]
LE = LabelEncoder()
LE.fit(_label_copy)
print(list(LE.classes_))
normalized_labels = LE.transform(_label_copy)
print(len(normalized_labels))
['Iris-setosa', 'Iris-versicolor', 'Iris-virginica']
150
from sklearn.neighbors import KNeighborsClassifier
DATA = _data_copy
DATA = [np.array(DATA[i][:-1]) for i in range(len(DATA))]
DATA = np.array(DATA)
DATA.shape
(150, 4)
Now let’s split our dataset into a training and test sets:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
DATA, normalized_labels, test_size=0.5, random_state=1000
)
KNN = KNeighborsClassifier(n_neighbors=7)
KNN.fit(X_train, y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=7, p=2,
weights='uniform')
indices = KNN.predict(X_test)
prediction = [LE.classes_[i] for i in indices]
KNN.score(X_test, y_test)
0.96
_frac_ = np.linspace(0.05, 0.9, 100)
accuracy = np.zeros(len(_frac_))
for i, _f_ in enumerate(_frac_):
X_train, X_test, y_train, y_test = train_test_split(
DATA, normalized_labels, test_size=1-_f_, random_state=150
)
KNN = KNeighborsClassifier(n_neighbors=5, algorithm="brute")
KNN.fit(X_train, y_train)
accuracy[i] = KNN.score(X_test, y_test)
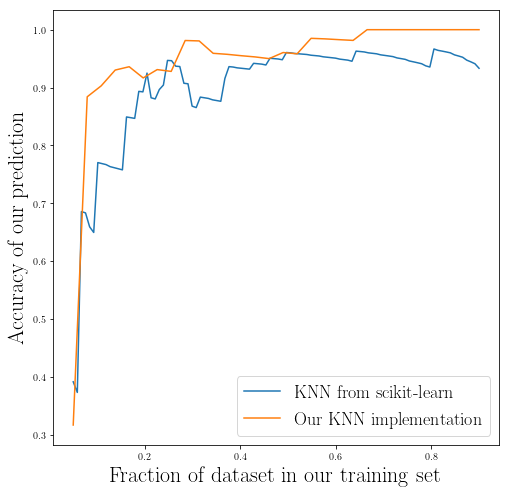
fig_training_frac_accuracy = plt.figure(figsize=(8, 8))
plt.plot(_frac_, accuracy, label="KNN from scikit-learn")
plt.plot(_t_1, _acc_1, label="Our KNN implementation")
plt.xlabel(r"Fraction of dataset in our training set", fontsize = 22)
plt.ylabel(r"Accuracy of our prediction", fontsize = 22)
plt.legend(fontsize=18)
plt.show()
X_train, X_test, y_train, y_test = train_test_split(
DATA, normalized_labels, test_size=0.2, random_state=150
)
K_span = np.arange(1, len(X_train), 1)
accuracy = np.zeros(len(K_span))
for i, k in enumerate(K_span):
KNN = KNeighborsClassifier(n_neighbors=k, algorithm="brute")
KNN.fit(X_train, y_train)
accuracy[i] = KNN.score(X_test, y_test)
fig_training_frac_accuracy = plt.figure(figsize=(8, 8))
plt.plot(K_span, accuracy, label = "KNN from scikit-learn")
plt.plot(k_2, _acc_2, label="Our KNN implementation")
plt.xlabel(r"Number of Neighbours (k)", fontsize = 22)
plt.ylabel(r"Accuracy of our prediction", fontsize = 22)
plt.legend(fontsize=15)
plt.show()
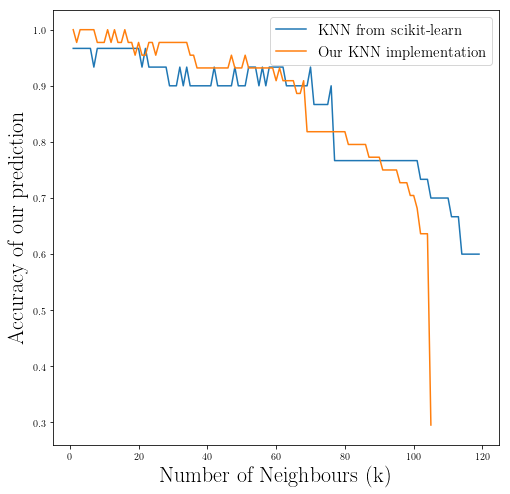
As you can see our implementation performance is fairly close to the performance of the KNN from the scikit-learn library.
« Go to Week 4
Go to Week 6 »
References:
https://docs.scipy.org/doc/scipy/reference/cluster.hierarchy.html](https://docs.scipy.org/doc/scipy/reference/cluster.hierarchy.html)
https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html